



Photo by Google DeepMind on Unsplash
Reinforcement Learning and Q-Learning
Implementing Reinforcement Learning with Q-Learning and Epsilon Greedy Policy!


Introduction
The majority of people have utilized streaming services like Disney Plus, Netflix, and YouTube. These services use a recommendation system to keep you on their website and amused. This algorithm uses the content you've recently watched to propose similar content that could be of interest to you. These algorithms for content recommendations are frequently reinforcement learning models.
Vocabulary Words
Before we continue, I think it will benefit us all to learn some essential reinforcement learning vocabulary words.
Agent: The reinforcement learning model that is making the decisions
Environment: The external system/area that the agent is getting its data from
Reward: The human feedback from the environment
State: The environment at a specific time (kind of like one picture frame of a video).
Action: The response of the agent to a state using its policy
Policy: Maps an observation to an action, basically how the model converts a human action to its response
(Q-Learning term) Q-Table: A table that maps actions to states/observations, this will help the agent determine what the best action to do for a given state.
What is Reinforcement Learning?
Reinforcement Learning is a type of machine learning that tries to maximize receiving a reward by leveraging information from its environment. In streaming services, the agent aims to increase customer engagement. When you are asked to rate your experience with something on YouTube, it typically appears in a popup that looks like this:
With a popup similar to the one above, you might tell YouTube's recommendation algorithm that you didn't like a video or didn't think it was worth watching. This information would likely be added to your state. Consequently, the recommendation engine would be less likely to suggest items that you would enjoy. Contrarily, giving a movie or experience positive comments would encourage the model to show you more of that kind of content (and result in a better reward for the agent).
An Example of Reinforcement Learning
Let's say we're trying to build a Reinforcement learning model that aims to recommend videos of interest to users that they will watch for as long as possible (to increase user engagement times).
In this example, the state for each user will consist of the video they may be watching right now, and previous videos to demonstrate their interests (I only added the most recent two videos for convenience). However, the state may be affected by many additional variables in more complicated circumstances, such as location, language, weather, and time of day.
The reward for this could be a variety of things, but in this example, it will be determined by how many minutes of a recommended video a user watches divided by the total number of minutes in the video (minutes watched by the user / total minutes in the video), with a decimal value ranging from 0 to 1. In this case, the reward for watching 100% of the movie would be 1, 0.5 for watching 50% of the video, 0.25 for watching 25% of the film, etc. A chart with various examples of user states and rewards is shown below.
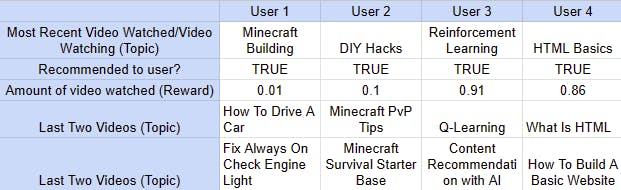
People who aren't recommended the videos they usually watch are likely to lose interest in the recommended videos quickly. To maintain user interest, it is crucial for these content recommendation bots to suggest to the user what they want. Users 1 and 2 were provided with videos that were obviously unrelated to their interests, as shown in the chart above (humans can easily determine their interests based on their watch history).
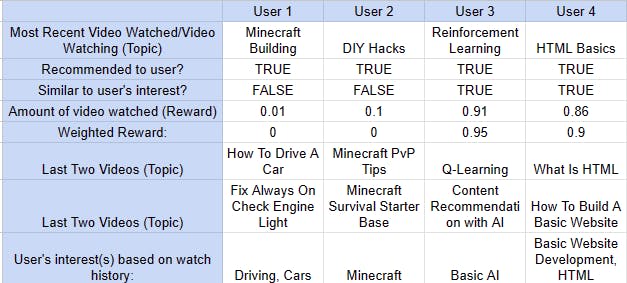
There are a few modifications that might be made to this system to make it more sophisticated, one of which is to give rewards weights (weighted rewards). In the given case, this involves rewarding the agent more generously the longer a user views the recommended video. However, if the video is of the user's interest, then the reward should also be increased. In this manner, the agent is more likely to suggest videos that the user will find interesting. Some readers may be wondering how a non-human AI could tell the topic of a video. How a non-human AI could identify the content of a video may be a mystery to some readers. Sentiment Analysis is a tool used in Natural Language Processing (NLP) that can extract thoughts, feelings, and opinions from text, but we won't discuss that in this post because it is a totally different topic. Returning to the topic of weighted rewards, the table shown above allows us to monitor the user's interest (see an example of this table below). We can check to see if the title and description of the video the user is watching are related to their interest(s) before deciding what to reward the agent for the user's watch time. Additionally, it means that the agent will be given additional consequences for suggesting a video that is unrelated to the user's interests.
How the Agent Maximizes its Reward
There is one significant question I have not addressed yet. Which is how does the agent maximize its reward? In our example, the agent would receive some feedback from the user (such as watch time, likes and dislikes, star ratings, or ratings from a popup) and "re-train" itself (correct its decision-making policy) to take into account said feedback in future actions. In doing so, it iteratively gets better and improves its policy. Improvements to an agent's policy would look something like this:
Iteration 0: Recommend trending videos on the platform (To User X)
Iteration 1: Recommend Minecraft videos (To User X)
Iteration 2: Recommend Minecraft Survival videos (To User X)
Iteration 3: Recommend Minecraft Survival PvP videos (To User X)
It repeats this cycle with a large number of users, and with time the policy begins to get better and better, eventually producing a content recommendation agent that amuses the users fairly effectively.
Another Example of How the Agent Maximizes its Reward
To make it easier to highlight iteratively improving an agent's policy, here's another example:
Consider creating a reinforcement learning model to move through a game without hitting any obstacles. The agent must navigate its way from a starting room to a finishing room. Moving forward, backward, left, and right are the possible actions in each state, which can be thought of as a room. If the agent encounters an obstacle, it receives a reward of -1; and if it beats the level, it receives a reward of 1. Additionally, all other transitions (events) would not be scored or would receive a little negative score, such as -0.01, because the only thing we want this agent to avoid colliding with is obstacles.
The first time the agent plays through the game, it would have a random policy that would cause it to lose with a reward of -1. However, over time, as the agent plays the game as explores its environment and the rewards that result from certain actions in certain states, it will develop a policy that can beat the game pretty well!
Q-Learning
Let's take a look at one of the most popular Reinforcement Learning algorithms called Q-Learning. Policy iteration is how Q-Learning functions. It operates on a table with dimensions equal to the number of potential states (rows) and actions (columns). If we attempted to apply Q-Learning in the example above, we would have a table with the number of rooms (the number of states) x the 4 (the number of actions.
The agent's Q-Table will initially contain just random integers, often 0s, as it has no way of understanding what the best action is in any given state. The agent will then do random actions and log its reward in the Q-Table. Later, when the agent is selecting which action to take, it will look at the Q-Table to see which action produced the best results for the state it is in at the time.
Q-Learning agents typically follow a formula similar to this:
$$Q^{new}(s_t, a_t) ← (1 - α) ⋅ Q(s_t, a_t) + α\left(r_t + γ ⋅ maxQ\left(s_{t+1},a \right) \right)$$
I will explain the different letters you see in the formula above.
$$Q \text { means the Q-table}$$
$$_t \text { means at that specific time}$$
$$s \text { means state}$$
$$a \text { (the English letter) means action}$$
$$r \text { means reward}$$
$$\gamma \text { means the discount factor (how much weight a reward carries)}$$
$$\alpha \text { (alpha, the Greek letter) means the learning rate}$$
Implementing Q-Learning!
I am unable to implement a full content recommendation system because it is a highly complex task. Instead, I'll be creating a very basic Q-Learning agent that can be used with the game "Frozen Lake" through the Python package "Gymnasium" (formerly known as "Gym"). The code will be shared step-by-step in this article, and for those who wish to execute or alter it, the Python (.py) and Jupyter file (.ipynb) downloads will be provided at the end.
Importing the Necessary Libraries
For our program to work, it is going to need some Python libraries, which will be imported in the code block below.
The libraries we are going to import are Numpy and Gymnasium (explained below).
Numpy is a very popular Python library that is used in a lot of situations. It is mainly used for its amazing scientific computational abilities on arrays. In this notebook, it will be used to maintain the Q-Table.
Gymnasium (which will be referred to as "Gym" for the duration of this article) is a Python library made by OpenAI (the company behind ChatGPT) that has many environments for training Reinforcement Learning models (such as this one).
# Bash command to install the libraries
!pip install numpy
!pip install gymnasium[toy-text] # The Frozen Lake game is classified as a "Toy Text" game in Gym
# If you are using the Python file please open your terminal and type in the commands above without the "!"
# Python code to import the libraries we will use later
import numpy as np
import gymnasium as gym
Setting Up the Gymnasium Environment
A reinforcement learning model needs to train itself. In this case, it has to train itself by playing the Frozen Lake game. In the code block below, we will be using OpenAI's Gym Python library to set up and "run" the Frozen Lake game.
# Make the environment
env = gym.make("FrozenLake-v1", map_name="4x4", render_mode="ansi", is_slippery=False)
# Reset the environment to get a observation
observation, info = env.reset()
# Printing the state
# When the observation is printed, you will see that we recieve the number 0 like mentioned above
print(observation)
Output: 0
In this game, there are four actions for our agent to do.
Move the character up
Move the character down
Move the character left
Move the character right
Every time we do an action in the environment, we will receive five pieces of information from the environment (since every action we take changes the state of the environment, we need to know the current state of the environment).
next_state: An observation from the environment also known as the state (explained more below)reward: The reward the agent should receive from the actionterminated: A true/false (boolean) value that shows whether or not the environment has been terminatedtruncated: A true/false (boolean) value that shows whether or not the game has been truncated (ended early), this usually happens because of a time limit.info: A dictionary (a collection of key-value pairs) that may contain additional information about the environment.
Of these five returned values, the first four will be the most useful to us.
We will receive an observation that consists of a single digit representing the player's position. The observation we get follows this formula: current_row * nrows + current_column. At the start, we will spawn in at row 0, col 0. Meaning our state will be 0 (the rows and cols are 0-indexed).
The reward the agent can be given for any action is 0 (for reaching a frozen lake square or reaching a hole) or 1 (reaching the goal square).
We can also render the game in ANSI, as seen below.
print(env.render())
# S is the starting point
# G is the goal
# H's are holes
# F's are the Frozen lake
# The letter with a red/pink background is the character's current position
Output:
SFFF
FHFH
FFFH
HFFG
# (in the output above the "S" has a pink background)
Moving on, we can now select a random action from the pool of possible actions (called the action space) and see what data we get in response:
# Now we will take a random action in the environment and see what we get in response
# Selecting a random action
action = env.action_space.sample()
# Executing that random action in the environment
observation, reward, terminated, truncated, info = env.step(action)
print(f"Observation: {observation}")
print(f"Reward: {reward}")
print(f"Environment Terminated?: {terminated}")
print(f"Environment Truncated?: {truncated}")
# Render the game
print("\n" + env.render())
# The character moving on it's own is simply random, next we will implement a RL model to make it play better!
Output:
Observation: 1
Reward: 0.0
Environment Terminated?: False
Environment Truncated?: False
(Up)
SFFF
FHFH
FFFH
HFFG
# (in the output above the "F" to the right of the "S" has a pink background)
By the way, here is how the Frozen Lake game is pictured on the Gymnasium website for those of us who learn best visually:

Creating the Q-Learning Agent
Next, we will implement Q-Learning, a popular Reinforcement Learning algorithm, along with the Epsilon Greedy Policy. The Epsilon Greedy Policy is what selects a random action for our agent (you'll see this soon).
Our Q-Table will initially be defined with only 0s; the agent will eventually replace these values.
# Initialize our Q-Table to all 0 values (the RL agent bases it's decisions off of this table and updates it in training)
QTable = np.zeros((env.observation_space.n, env.action_space.n))
Next, we'll declare the Epsilon Greedy Policy function.
# Greedy Epsilon Function, this is what determines what action we will take
def greedyEpsilon(Qtable, state, epsilon):
num = np.random.rand()
if (num < epsilon):
action = env.action_space.sample()
else:
action = np.argmax(Qtable[state])
return action
Then, to train our agent, we can declare and invoke another function.
# Now we will train our agent (this might take a few minutes)
def train(env, QTable, numOfEpisodes, learningRate, discountFactor, startingEpsilon, finalEpsilon, decayRate, maxSteps):
for i in range(numOfEpisodes):
# Decaying Epsilon so that we get more exploitation than exploration (over time)
epsilon = startingEpsilon + (finalEpsilon - startingEpsilon) * np.exp(-decayRate * i)
# Reset the environment and get an observation
currentState = env.reset()
currentState = currentState[0]
for j in range(maxSteps):
# Determine what action to take with the Greedy Epsilon function
action = greedyEpsilon(QTable, currentState, epsilon)
# Retrieve important info from environment and apply our action in the environment
newState, reward, terminated, truncated, info = env.step(action)
# Update the Q Table to reflect what the agent has learned
QTable[currentState][action] = (1 - learningRate) * QTable[currentState][action] + learningRate * (reward + discountFactor * np.max(QTable[newState]))
# If the game is terminated or truncated, finish this session (this "session" is often called an "episode")
if (terminated or truncated):
break
# Update the state we were basing everything off of, to the new state
currentState = newState
return QTable
train(env, QTable, 10000, 0.5, 0.97, 0.01, 1, 0.0005, 10000)
As a result of this function, this is how the Q-Table looks.
array([[0.832972 , 0.85873403, 0.85873403, 0.832972 ],
[0.832972 , 0. , 0.88529281, 0.85873403],
[0.85873403, 0.912673 , 0.85873403, 0.88529281],
[0.88529281, 0. , 0.85874801, 0.85873689],
[0.85873403, 0.88529281, 0. , 0.832972 ],
[0. , 0. , 0. , 0. ],
[0. , 0.9409 , 0. , 0.88529281],
[0. , 0. , 0. , 0. ],
[0.88529281, 0. , 0.912673 , 0.85873403],
[0.88529281, 0.9409 , 0.9409 , 0. ],
[0.912673 , 0.97 , 0. , 0.912673 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9409 , 0.97 , 0.912673 ],
[0.9409 , 0.97 , 1. , 0.9409 ],
[0. , 0. , 0. , 0. ]])
Now for the moment of truth. Evaluating our agent to see how good it is at playing Frozen Lake.
# Lets see how well our agent performs when playing the game
# Variables
numOfWins = 0
numOfLosses = 0
for i in range(100):
# Get the current state/observation
state = env.reset()
state = state[0]
for j in range(1000):
# Get the action from the QTable with the highest reward
action = np.argmax(QTable[state][:])
# Retrieve important info from environment and apply our action in the environment
newState, reward, terminated, truncated, info = env.step(action)
# If the reward equals 1 (we got to the goal) add one to the number of wins
# Else add one to the number of losses
if (reward == 1):
numOfWins += 1
else:
numOfLosses += 1
# If the game is terminated or truncated, finish this session (this "session" is often called an "episode")
if (terminated or truncated):
break
# Update the state we were basing everything off of, to the new state
state = newState
print(f"Number of wins: {numOfWins}")
print(f"Number of losses: {numOfLosses}")
And as a result, we get... *drum roll please***
Number of wins: 100
Number of losses: 500
Ouch...
Conclusion
As it is evident from the evaluation above (100 wins and 500 losses), our agent is not very effective. That is probably because I just trained it for a short period of time—about two minutes. A reinforcement learning agent gets better with more training because it has more time to play through scenarios and understand the environment. However, Google Colab probably doesn't have resources to let me train a reinforcement agent for a long period of time. I want to thank you for reading this post. I hoped this was interesting and that you learned something new about RLHF (reinforcement learning with human feedback) and Q-Learning!
Download
You can download a Python file (.py) or a Jupyter file (.ipynb) file if you want to run or modify this code. I strongly advise utilizing the Jupyter file because it divides the code into more legible pieces and has less print statements per block, making the output easier to understand.
To download either one please visit: https://github.com/devsai9/hashnode-downloads/tree/main/rlhf-and-qlearning-7-25-2023
Jupyter file: https://github.com/devsai9/hashnode-downloads/blob/main/rlhf-and-qlearning-7-25-2023/blog-rlhf-ipynbfile.ipynb
Python file: https://github.com/devsai9/hashnode-downloads/blob/main/rlhf-and-qlearning-7-25-2023/blog-rlhf-pyfile.py